Jul 22, 2023
This came up years ago for me as an interview question that I flubbed badly. The task was to write a simplified regular expression matching algorithm that would test if a given string matched the provided pattern. The set of valid patterns was considerably simplified from full regular expressions to be only matching single characters or the Kleene Star * which matched zero or more instances of the previous character.
I quickly put together an implementation that worked well greedily but stumbled on backtracking, which is needed to match patterns like "aa*a". This should match strings "aa", "aaa", aaaa", and so on. However, to match the final character it is necessary to not consume the final "a" with the Kleene star since this would exhaust the input before reaching the final term. I was not able to figure out how to do this and did not get the job.
Now I do know how to do this. This post documents how not just for the simple case above but also a much more complete set of patterns.
Preamble
In the end, the bit I was missing was backtracking. As the pattern is matched, the matching algorithm needs to track a state indicating both where it is in the input and where it is in the pattern. In greedy matching, only a single state is maintained and the match fails whenever the next term fails to match or the input is exhausted before reachind the end of the pattern. The latter is what happens in the example at the start, the "a*"" term gobbles up all the input "a"s leaving the final a in the pattern unmatched.
For a backtracking implmentation, the algorithm creates & tracks a set of states, each corresponding to one of several discrete choices that can be made during the algorithm. These states are advanced as input is parsed and the match fails when all of the states fail to match.
In the simple expression grammar above, the discrete choices are to either match or skip matching an additional "a" when (recursively) handling the Kleene Star.
So a backtracking algorithm needs to be able to keep track of multiple states, each indicating the input position and pattern position, advance each state through the input and cull those states whenever they fail to match. If any state reaches the end of the pattern, the string matches.
Pattern Representation
The matching algorithm I'll describe here is richer than the introductory example. It supports matching any specified character, a binary or '|' operator that matches either the left or right operand, a binary and '&' operator that matches both the left & right operand in order and the Kleene Star '*'. The first is a terminal node of the expression tree, while the '&', '|' and '*' operators are internal nodes.
In addition, a nop node '~' is another terminal that automatically matches but consumes no input. It is helpful for defining other operations, e.g. "a?" matches zero or one instances of character "a" and can be defined as "~|a". It also ensures that every non-terminal node has both left and right children.
Beyond this, there are number of other node types that are pretty easy to figure out once the above are handled.
To represent this, an array-based tree is used with each element containing the following structure:
struct node_t {
constexpr static int INVALID = -1;
int parent = INVALID;
int left = INVALID;
int right = INVALID;
type_t type = type_t::NOP;
int data = -1;
};
Parent, left and right are indices of the corresponding nodes in the array and are used to walk the tree when matching. node_t::INVALID is used to represent the parent of the root node. The data field is used by the character node to define what character to match in the input while the type indicates the type of node as defined below:
enum type_t { NOP, CHAR, ANY, END, AND, OR, STAR, PLUS };
State Representation
This is enough to define tree but it is still necessary to track the matching algorithm state. To perform the matching, the algorithm walks the tree down to the left most terminal. If the terminals matches, it walks back up to the terminal's parent. Depending on the node type, it then either evaluates the right child or walks up to it's parent.
The algorithm state representation used is the currently visited node and the node that it arrived from as well as the current position in the input. This is enough to know both where in the tree we are and where we came from, which is enough to know what needs to be evaluated next.
In this algorithm, these states are tracked via a matching stack:
// stack entries are {input_pos, current_node, previous_node}
using match_stack_t = std::stack<std::tuple<const char*,int,int>>;
Matching Algorithm via Tree Traversal
By knowing where we are in the input and where we are in the tree and how we got there, we can implement the matching recursively. However, it is not desireable to actually use recursion because we could end up exhausting the call stack on long inputs. Instead we use a stack as above (and potentially exhaust memory instead).
At each iteration, we will pull a state from the stack. First we will check if we've exhausted the input string. If so the current state is culled. Then we will check if we've successfully processed the root node after recursing back up the tree. If so and input was consumed from the string, we've successfully matched the expression. Otherwise the state is culled.
result_t match( const char *input ) const {
match_stack_t stack;
const int n = strlen(input)+1;
// tree is built in post-fix order so root is last node
stack.push({input,int(_tree.size())-1,node_t::INVALID});
while( !stack.empty() ){
auto [str,node,last] = stack.top();
stack.pop();
if( str-input >= n ){
// exhausted input, consider remaining states
continue;
} else if( node == node_t::INVALID ){
// finished recursing back to root
if( str != input ){
// consumed input, successfully matched
return {true,str};
}
// did not consume input, match failed, try
// remaining states
continue;
}
switch( _tree[node].type ){
case type_t::NOP:
walk_nop( stack, str, node, last );
break;
case type_t::CHAR:
walk_char( stack, str, node, last );
break;
... other node types ...
case type_t::AND:
walk_and( stack, str, node, last );
break;
case type_t::OR:
walk_or( stack, str, node, last );
break;
case type_t::STAR:
walk_star( stack, str, node, last );
break;
... other node types ...
}
}
// exhausted regular expression or input
return {false,input};
}
Following this, we traverse the tree according to a set of rules for each node. The rules depend on the node type. The one common theme is that on a successful match at a subtree a new state is pushed with the input position and starting at the subtree's parent arriving from the subtree. However, when the subtree does not match, it does not push a new state and the state is culled.
For example, if we are at an '&' node and came from the '&' node's parent, we need to evaluate the left subtree. If we arrived from the left subtree, we need to evaluate the right subtree. Finally if we arrived from the right subtree, we need to go back up to the '&' node's parent.
void walk_and( match_stack_t& stack, const char* str, int node, int last ) const {
if( last == node_t::INVALID || last == _tree[node].parent ){
stack.push({str,_tree[node].left,node});
} else if( last == _tree[node].left ){
stack.push({str,_tree[node].right,node});
} else if( last == _tree[node].right ){
stack.push({str,_tree[node].parent,node});
} else {
assert( false && "Should never happen. Tree is borked!");
}
}
If, however, we are at an '|' node we first check the left subtree. If it matches, we recurse back up to the '|' node's parent and skip checking the right operand. This is done by pushing both left and right nodes onto the stack at the current position, if the left traveral fails, the algorithm will pop the right state and proceed from there. If we sucessfully arrive back at the '|' node from either of the subtrees, the match succeeded and we head back up to the parent node:
void walk_or( match_stack_t& stack, const char* str, int node, int last ) const {
if( last == node_t::INVALID || last == _tree[node].parent ){
stack.push({str,_tree[node].right,node});
stack.push({str,_tree[node].left, node});
} else if( last == _tree[node].left || last == _tree[node].right ){
stack.push({str,_tree[node].parent,node});
} else {
assert( false && "Should never happen. Tree is borked!");
}
}
The Kleene Star is similar to the '|' case except whenever we arrive at the '*' node we push both its parent and its left subtree. The order these are pushed determines whethe the '*' is greedy (tries to consume as much input as possible) or non-greedy (tries to consume as little as possible). This is the greedy version since it will retry the left subtree before recursing back to the parent.
void walk_star( match_stack_t& stack, const char* str, int node, int last ) const {
if( last == node_t::INVALID || last == _tree[node].parent ){
stack.push({str,_tree[node].parent, node});
stack.push({str,_tree[node].left, node});
} else if( last == _tree[node].left ){
stack.push({str,_tree[node].parent,node});
stack.push({str,_tree[node].left, node});
} else {
assert( false && "Should never happen. Tree is borked!");
}
}
Finally to pull it all together, there need to be the correponding implmentations for the '~' and character terminals. In the case of the nop, the string position remains the same and we move back to the parent node. The character node is almost the same, except we only recurse back if the next input character matches. In that case, we advance the string and recurse back to the parent node. Otherwise, the match for this state does not continue. These are:
void walk_nop( match_stack_t& stack, const char* str, int node, int last ) const {
stack.push({str,last,node});
}
void walk_char( match_stack_t& stack, const char* str, int node, int last ) const {
if( *str == _tree[node].data ){
stack.push({str+1,last,node});
}
}
Aside from some boilerplate to actually build the tree, the definition of the result type and a class to wrap it all together, that's really all there is to it.
The full example, including additional node types, is below
Full Example Source Code
#include <string>
#include <cassert>
#include <iostream>
#include <stack>
#include <tuple>
#include <vector>
class regex_t {
public:
struct result_t {
bool result;
const char* remainder;
operator bool() const { return result; }
operator const char*() const { return remainder; }
};
result_t match( const char *input ) const {
match_stack_t stack;
const int n = strlen(input)+1;
// tree is built in post-fix order so root is last node
stack.push({input,int(_tree.size())-1,node_t::INVALID});
while( !stack.empty() ){
auto [str,node,last] = stack.top();
stack.pop();
if( str-input >= n ){
// exhausted input, consider remaining states
continue;
} else if( node == node_t::INVALID ){
// finished recursing back to root
if( str != input ){
// consumed input, successfully matched
return {true,str};
}
// did not consume input, match failed, try
// remaining states
continue;
}
switch( _tree[node].type ){
case type_t::NOP:
walk_nop( stack, str, node, last );
break;
case type_t::CHAR:
walk_char( stack, str, node, last );
break;
case type_t::ANY:
walk_any( stack, str, node, last );
break;
case type_t::END:
walk_end( stack, str, node, last );
break;
case type_t::AND:
walk_and( stack, str, node, last );
break;
case type_t::OR:
walk_or( stack, str, node, last );
break;
case type_t::STAR:
walk_star( stack, str, node, last );
break;
case type_t::PLUS:
walk_plus( stack, str, node, last );
break;
}
}
// exhausted regular expression or input
return {false,input};
}
int nop(){
return add_terminal( {.type=type_t::NOP} );
}
int character( const char match ){
assert( match > 0 );
return add_terminal( {.type = type_t::CHAR, .data = match} );
}
int any(){
return add_terminal( {.type = type_t::ANY } );
}
int end(){
return add_terminal( {.type = type_t::END} );
}
int both( const int left, const int right ){
return add_tree( {.type = type_t::AND}, left, right );
}
int either( const int left, const int right ){
return add_tree( {.type = type_t::OR}, left, right );
}
int star( const int left ){
return add_tree( {.type = type_t::STAR}, left, nop() );
}
int plus( const int left ){
return add_tree( {.type = type_t::PLUS}, left, nop() );
}
int maybe( const int left ){
return either( left, nop() );
}
private:
using match_stack_t = std::stack<std::tuple<const char*,int,int>>;
enum type_t { NOP, CHAR, ANY, END, AND, OR, STAR, PLUS };
struct node_t {
constexpr static int INVALID = -1;
int parent = INVALID;
int left = INVALID;
int right = INVALID;
type_t type = type_t::NOP;
int data = -1;
};
void walk_nop( match_stack_t& stack, const char* str, int node, int last ) const {
stack.push({str,last,node});
}
void walk_char( match_stack_t& stack, const char* str, int node, int last ) const {
if( *str == _tree[node].data ){
stack.push({str+1,last,node});
}
}
void walk_any( match_stack_t& stack, const char* str, int node, int last ) const {
if( *str != '\0' ){
stack.push({str+1,last,node});
}
}
void walk_end( match_stack_t& stack, const char* str, int node, int last ) const {
if( *str == '\0' ){
stack.push({str,last,node});
}
}
void walk_and( match_stack_t& stack, const char* str, int node, int last ) const {
if( last == node_t::INVALID || last == _tree[node].parent ){
stack.push({str,_tree[node].left,node});
} else if( last == _tree[node].left ){
stack.push({str,_tree[node].right,node});
} else if( last == _tree[node].right ){
stack.push({str,_tree[node].parent,node});
} else {
assert( false && "Should never happen. Tree is borked!");
}
}
void walk_or( match_stack_t& stack, const char* str, int node, int last ) const {
if( last == node_t::INVALID || last == _tree[node].parent ){
stack.push({str,_tree[node].right,node});
stack.push({str,_tree[node].left, node});
} else if( last == _tree[node].left || last == _tree[node].right ){
stack.push({str,_tree[node].parent,node});
} else {
assert( false && "Should never happen. Tree is borked!");
}
}
void walk_star( match_stack_t& stack, const char* str, int node, int last ) const {
if( last == node_t::INVALID || last == _tree[node].parent ){
stack.push({str,_tree[node].parent, node});
stack.push({str,_tree[node].left, node});
} else if( last == _tree[node].left ){
stack.push({str,_tree[node].parent,node});
stack.push({str,_tree[node].left, node});
} else {
assert( false && "Should never happen. Tree is borked!");
}
}
void walk_plus( match_stack_t& stack, const char* str, int node, int last ) const {
if( last == node_t::INVALID || last == _tree[node].parent ){
stack.push({str,_tree[node].left, node});
} else if( last == _tree[node].left ){
stack.push({str,_tree[node].parent,node});
stack.push({str,_tree[node].left, node});
} else {
assert( false && "Should never happen. Tree is borked!");
}
}
// builder stuff
int add_terminal( const node_t& n ){
_tree.emplace_back( n );
return _tree.size()-1;
}
int add_tree( const node_t& n, int left, int right ){
assert( left >= 0 && left < _tree.size() && right >= 0 && right < _tree.size() );
int parent = add_terminal( n );
_tree[parent].left = left;
_tree[parent].right = right;
_tree[ left].parent = parent;
_tree[right].parent = parent;
return parent;
}
std::vector<node_t> _tree;
};
std::ostream& operator<<( std::ostream& os, const regex_t::result_t& res ){
os << (res.result ? "match succeeded" : "match_failed") << ", remainder: \"" << res.remainder << "\"" << std::endl;
return os;
}
int main( int argc, char **argv ){
regex_t re;
re.both(
re.character('a'),
re.both(
re.plus(
re.character('a')
),
re.both(
re.character('a'),
re.end()
)
)
);
std::cout << re.match("aaa") << std::endl;
return 0;
}
Apr 09, 2023
This was mildly fiddly so I'm putting information here.
First set your home router to pass ports 80 and 443 to the target machine. Verify that you have done this successfully by trying to connect from a machine that is outside your LAN, e.g. a mobile phone using cell rather than wifi, to your (current) public IP. To do this, I use Python's built-in http server:
cat 'hello world' > index.html
python3 -m http.server
Connect to your IP from outside your LAN and you should see hello world in your browers. Assuming that was successful and that your server is a Ubuntu/Debian-based machine, install ddclient:
sudo apt install ddclient
It will guide you through setup but for me it did not work. You might be tempted to use the google domains option but this did not work for me. Try it anyway and if/when it fails use something like the following. Do not include http:// or https:// in the <your domain> portion.
protocol=dyndns2
use=web
server=domains.google.com
ssl=yes
login='<google-generated-login>'
password='<google-generated-password>'
<your domain>
The login and password fields are not your Google account username and password. They are generated by Google. Open your domain in Google domains and go to the DNS section, then scroll down to and enable Show Advanced Settings and then expnd the Dynamic DNS collapsed panel. Then click View Credentials (red arrow below) and you should see the following. You can get your login/password by clicking View on the panel that pops up.
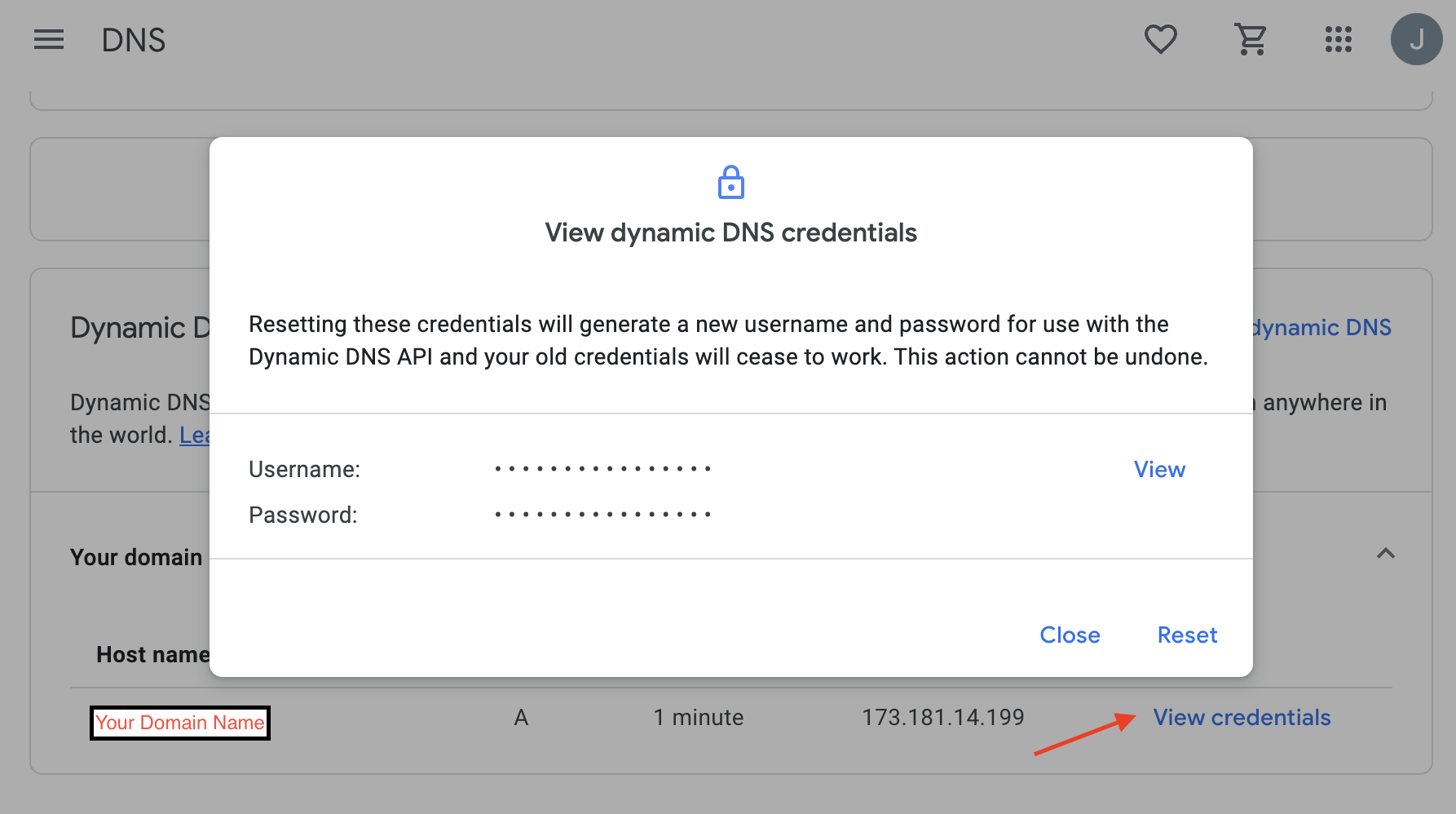
You can then run:
sudo service ddclient restart
to restart ddclient and run:
sudo ddclient query
to perform an update. Refreshing the google domains page for the domain should ideally show that the record has been updated. Using your external-to-your-LAN-machine, you should now
Jun 09, 2022
Given two matrices \(A \in \mathcal{R}^{M\times S}\) and \(B \in \mathcal{R}^{S \times N}\) it is helpful to be able to reorder their product \(A B \in \mathcal{R}^{M\times N}\) in order to compute Jacobians for optimization. For this it is common to define the \(\mbox{vec}(.)\) operator which flattens a matrix into a vector by concatenating columns:
\begin{equation*}
\newcommand{\vec}[1]{\mbox{vec}{\left(#1\right)}}
\vec{A} = \begin{bmatrix} A_{11} \\ \vdots \\ A_{M1} \\ \vdots \\ A_{1S} \\ \vdots \\ A_{MS}\end{bmatrix}
\end{equation*}
Using this operator, the (flattened) product \(AB\) can be written as one of:
\begin{align*}
\vec{AB} &=& (B^T \otimes I_A)\vec{A} \\
&=& (I_B \otimes A)\vec{B}
\end{align*}
where \(\otimes\) is the Kronecker Product and \(I_A\) is an identity matrix with the same number of rows as \(A\) and \(I_B\) is an idenity matrix with the same number of columns as \(B\).
From the two options for expressing the product, it's clear that \((B^T \otimes I_A)\) is the (vectorized) Jacobian of \(AB\) with respect to \(A\) and \((I_B \otimes A)\) is the corresponding vectorized Jacobian with respect to \(B\).
That's great but if our linear algebra library happens to represent matrices in row-major order it will be necessary to sprinkle a large number of transposes in to get things in the right order to apply these formulas. That will be tedious, error-prone and inefficient. Fortunately, equivalent formulas are available for row-major ordering by defining a \(\mbox{ver}(.)\) operator that flattens a matrix by concatenating rows to form a column vector:
\begin{equation*}
\newcommand{\ver}[1]{\mbox{ver}{(#1)}}
\ver{A} = \begin{bmatrix} A_{11} \\ \vdots \\ A_{1S} \\ \vdots \\ A_{M1} \\ \vdots \\ A_{MS} \end{bmatrix}
\end{equation*}
Given this it is fairly quick to work out that the equivalent to the first two formulas using the \(\ver{.}\) operator are:
\begin{align*}
\ver{AB} &=& (I_A \otimes B^T)\ver{A} \\
&=& ( A \otimes I_B)\ver{B}
\end{align*}
Using the same logic it can be concluded that \((I_A \otimes B^T)\) is the vectorized Jacobian of \(AB\) with respect to \(A\) and \((A \otimes I_B)\) is the corresponding Jacobian with respect to \(B\).
It's also worth noting that these are simplifications of a more general case for the product \(AXB\) that brings \(X\) to the right of the expression. The corresponding \(\vec{.}\) and \(\ver{.}\) versions are:
\begin{align*}
\vec{AXB} &=& (B^T \otimes A) \vec{X} \\
\ver{AXB} &=& (A \otimes B^T) \ver{X}
\end{align*}
which makes it clear where the identity matrices \(I_A\) and \(I_B\) in the previous expressions originate.
All these can be demonstrated by the following python code sample:
from typing import Tuple
import numpy as np
def vec( M: np.ndarray ):
'''Flatten argument by columns'''
return M.flatten('F')
def ivec( v: np.ndarray, shape: Tuple[int,int] ):
'''Inverse of vec'''
return np.reshape( v, shape, 'F' )
def ver( M: np.ndarray ):
'''Flatten argument by rows'''
return M.flatten('C')
def iver( v: np.ndarray, shape: Tuple[int,int] ):
'''Inverse of ver'''
return np.reshape( v, shape, 'C' )
def test_vec_ivec():
A = np.random.standard_normal((3,4))
assert np.allclose( A, ivec( vec( A ), A.shape ) )
def test_ver_iver():
A = np.random.standard_normal((3,4))
assert np.allclose( A, iver( ver(A), A.shape ) )
def test_products():
A = np.random.standard_normal((3,4))
X = np.random.standard_normal((4,4))
B = np.random.standard_normal((4,5))
AB1 = A@B
Ia = np.eye( A.shape[0] )
Ib = np.eye( B.shape[1] )
AB2a = ivec( np.kron( B.T, Ia )@vec(A), (A.shape[0],B.shape[1]) )
AB2b = ivec( np.kron( Ib, A )@vec(B), (A.shape[0],B.shape[1]) )
assert np.allclose( AB1, AB2a )
assert np.allclose( AB1, AB2b )
AB3a = iver( np.kron( A, Ib )@ver(B), (A.shape[0], B.shape[1]) )
AB3b = iver( np.kron( Ia, B.T )@ver(A), (A.shape[0], B.shape[1]) )
assert np.allclose( AB1, AB3a )
assert np.allclose( AB1, AB3b )
AXB1 = A@X@B
AXB2 = ivec( np.kron(B.T,A)@vec(X), (A.shape[0],B.shape[1]) )
AXB3 = iver( np.kron(A,B.T)@ver(X), (A.shape[0],B.shape[1]) )
assert np.allclose( AXB1, AXB2 )
assert np.allclose( AXB1, AXB3 )
if __name__ == '__main__':
test_vec_ivec()
test_ver_iver()
test_products()
Hopefully this is helpful to someone.
Dec 03, 2021
These are some helpful quaternion identities, all summarized from Kok et al., Using Inertial Sensors for Position and Orientation Estimation although I have put the scalar component last.
A quaternion \(q\) is represented as a 4-tuple, or an imaginary vector portion \(q_v=[q_x,q_y,q_z]^T\) and a scalar value \(q_s\) giving \(q = [q_v^T, q_s]^T\). The norm of a quaternion is \(\|q\|_2 = (q_v^T q_v + q_s^2)^{\frac{1}{2}}\), the conjugate of a quaternion is \(q^* = [-q_v^T, q_s]^T\) and the inverse of a quaternion is \(q^{-1} = \frac{q^*}{\|q\|_2^2}\).
Unit quaternions have \(\|q\|_2 = 1\), in which case \(q^* = q^{-1}\). Unit quaternions also represent spatial rotations/orientations of \(\theta\) radians around a unit axis \(a\) via \(q = [a^T \sin\left(\frac{\theta}{2}\right), \cos\left(\frac{\theta}{2}\right) ]^T\). Both \(q\) and \(-q = [-q_v, -q_s]^T\) represent the same orientation, although the one with positive scalar component takes the shortest rotation to achieve that orientation since \(\cos^{-1}(|x|) \leq \cos^{-1}(-|x|)\).
The multiplication of two quaternions is \(p \otimes q = [ (p_s q_v + q_s p_v + p_v \times q_v)^T, p_s q_s - p_v \times q_v ]^T\). The presence of the cross-product means that \(p\otimes q \neq q \otimes p\). When \(p, q\) are unit quaternions, \(p\otimes q\) is equivalent to chaining the two rotations. The rotation matrix corresponding to a unit quaternion is:
\begin{equation*}
R(q) = \begin{bmatrix} 1 - 2 q_y^2 - 2*q_z^2 & 2 q_x q_y - 2 q_z q_s & 2 q_x q_z + 2 q_y q_s \\
2 q_x q_y + 2 q_z q_s & 1 - 2 q_x^2 - 2 q_z^2 & 2 q_y q_z - 2 q_x q_s \\
2 q_x q_z - 2 q_y q_s & 2 q_y q_z + 2 q_x q_s & 1 - 2 q_x^2 - 2 q_y^2 \end{bmatrix}
\end{equation*}
or in python:
def quat2mat( q: np.ndarray ) -> np.ndarray:
assert q.ndim == 1 and q.size == 4
qx,qy,qx,qs = q
return np.ndarray((
( 1 - 2*qy**2 - 2*qz**2, 2*qx*qy - 2*qz*qs, 2*qx*qz + 2*qy*qs ),
( 2*qx*qy + 2*qz*qs, 1 - 2*qx**2 - 2*qz**2, 2*qy*qz - 2*qx*qs ),
( 2*qx*qz - 2*qy*qs, 2*qy*qz + 2*qx*qs, 1 - 2*qx**2 - 2*qy**2 )
))
The, usually non-unit, quaternion representation of a vector \(v^\wedge = [ v^T, 0]^T\). The vector can be rotated by the unit-quaternion \(q\) via \(R(q) v = (q\otimes v^\wedge \otimes q^*)_v\) where only the vector portion is retained.
The quaternion-quaternion product can be represented by matrix multiplication in either the same, or reversed order, i.e.:
\begin{align*}
\newcommand{\pd}[2]{\frac{\partial #1}{\partial #2}}
p \otimes q &= p^L q = q^R p \hspace{1cm} & \mbox{where} \\
p^L &= \begin{bmatrix} p_s I + \lfloor p_v \rfloor_\times & p_v \\ -p_v^T & p_s \end{bmatrix} & \\
q^R &= \begin{bmatrix} q_s I - \lfloor q_v \rfloor_\times & q_v \\ -q_v^T & q_s \end{bmatrix} &
\end{align*}
where \(\lfloor m \rfloor_\times\) is the matrix representation of the cross-product. This is extremely useful when differentiating quaternion expressions since \(p^L = \pd{}{q}(p\otimes q)\) and \(q^R = \pd{}{p}(p\otimes q)\).
A Rodrigues rotation vector \(\eta = \theta a\) where \(\|a\|_2 = 1\) can be mapped to a quaternion via the exponential map:
\begin{align*}
\exp_q(\eta) =& q = \begin{pmatrix} a \sin\left(\frac{\theta}{2}\right) \\ \cos\left(\frac{\theta}{2}\right) \end{pmatrix} \\
\log_q(q) =& \eta = 2 q_v
\end{align*}
Under the assumption that \(\theta << 1\), the following approximations can be made:
\begin{align*}
\exp_q(\eta) \approx& \begin{pmatrix} \frac{\eta}{2} \\ 1 \end{pmatrix} \\
\pd{\exp_q(\eta)}{\eta} \approx& \begin{pmatrix} \frac{1}{2} I_{3\times3} \\ 0 \end{pmatrix} \\
\pd{\log_q(q)}{q} \approx& \begin{pmatrix} 2 I_{3\times3} & 0_{3\times1} \end{pmatrix}
\end{align*}
The above are also very helpful in manifold optimization over quaternion states where the Newton update is generally small which results in linear Jacobians with respect to the update variables.
Nov 28, 2021
I find this process easier to reason through by writing out a small 3-column version explicitly:
\begin{equation*}
\begin{bmatrix} A_{*0} & A_{*1} & A_{*2} \end{bmatrix} =
\begin{bmatrix} Q_{*0} & Q_{*1} & Q_{*2} \end{bmatrix} \begin{bmatrix}
R_{00} & R_{01} & R_{02} \\
& R_{11} & R_{12} \\
& & R_{22}
\end{bmatrix}
\end{equation*}
which gives:
\begin{align*}
&A_{*0} = Q_{*0} R_{00} \\
&A_{*1} = Q_{*0} R_{01} + Q_{*1} R_{11} \\
&A_{*2} = Q_{*0} R_{02} + Q_{*1} R_{12} + Q_{*2} R_{22}
\end{align*}
From this and the orthonormal properties of \(Q\), the meaning of the \(R_{ji}\) values are clear, the projection of the \(i\)'th column of \(A\) onto the \(j\)'th column of \(Q\). These allows fixing the values of \(R_{ji}\) and norms of \(Q_{*i}\):
- \(Q_{*i}^T Q_{*j} = 0, \forall i \neq j\): columns of \(Q\) are orthogonal so each \(R_{j*}\) value must account for entire parallel component of \(A_{*j}\) onto each column of \(Q\).
- \(\|Q_{*i}\|_2 = 1, \forall i\): constrains \(\|Q_{*i}\|\) and corresponding \(R_{ji}\) values.
Therefore:
- \(R_{00} = \|A_{*0}\|_2\) and \(Q_{*0} = A_{*0}/R_{00}\)
- \(R_{01} = Q_{*0}^T A_{*1}\), \(s_1 = A_{*1} - R_{01} Q_{*0}\), \(R_{11} = \|s_1\|_2\) \(Q_{*1} = s_1/R_{11}\)
- \(R_{02} = Q_{*0}^T A_{*2},~R_{12} = Q_{*1}^T A_{*2}, s_2 = A_{*2} - R_{02} Q_{*0} - R_{12} Q_{*1}, R_{22} = \| s_2 \|_2, Q_{*2} = s_2/R_{22}\)
or in general:
- \(R_{ji} = Q_{*j}^T A_{*i}, \forall j < i\)
- \(s_{i} = A_{*i} - \sum_j R_{ji} Q_{*j}\)
- \(R_{ii} = \| s_{i} \|_2, Q_{*i} = s_i/R_{ii}\)
and in python:
def qr_gs( A, inplace=True ):
'''Decompose A into Q*R with Q orthonormal and R upper triangular using classical Gram-Schmidt (unstable)'''
A = A if inplace else A.copy()
R = np.zeros((A.shape[1],A.shape[1]))
for i in range( A.shape[1] ):
for j in range(i):
R[j,i] = np.sum(A[:,j]*A[:,i])
A[:,i] -= R[j,i]*A[:,j]
R[i,i] = np.linalg.norm(A[:,i])
A[:,i] /= R[i,i]
return A,R
The form above generates \(Q\) column by column but has stability issues due to the use of classical Gram-Schmidt. It can be improved by replacing classical Gram-Schmidt with modified Gram-Schmidt:
def qr_mgs( A, inplace=True ):
'''Decompose A into Q*R with Q orthonormal and R upper triangular using modified Gram-Schmidt
Assumes columns of A are linearly independent.
'''
A = A if inplace else A.copy()
R = np.zeros((A.shape[1],A.shape[1]))
for i in range( A.shape[1] ):
R[i,i] = np.linalg.norm(A[:,i])
A[:,i] /= R[i,i]
for j in range(i+1,A.shape[1]):
R[i,j] = np.dot(A[:,j],A[:,i])
A[:,j] -= R[i,j]*A[:,i]
return A,R
The inner loop of this can be replaced entirely with vectorization in python but the above form gives a reasonable starting point for porting to another language like C or C++. These implementations should also check for \(R_{ii} = 0\) which indicate a rank deficient system.
Jun 14, 2021
Given a linear model \(y_i = x_i^T \beta\), we collect \(N\) observations \(\tilde{y_i} = y_i + \epsilon_i\) where \(\epsilon_i \sim \mathcal{N}(0,\sigma^2)\). The likelihood of any one of our observations \(\tilde{y_i}\) given current estimates of our parameters \(\beta\) is then:
\begin{equation*}
\newcommand{\exp}[1]{{\mbox{exp}\left( #1 \right)}}
\newcommand{\log}[1]{{\mbox{log}\left( #1 \right)}}
\DeclareMathOperator*{\argmax}{argmax}
\DeclareMathOperator*{\argmin}{argmin}
P(\tilde{y}_i | \beta) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp{-\frac{1}{2}\left(\frac{e_i}{\sigma}\right)^2} = \frac{1}{\sqrt{2\pi\sigma^2}} \exp{-\frac{1}{2}\left(\frac{\tilde{y_i}-x_i^T \beta}{\sigma}\right)^2}
\end{equation*}
and the likelihood of all of them occuring is:
\begin{equation*}
P(\tilde{y} | \beta) = \prod_{i=1}^N P(\tilde{y}_i | \beta )
\end{equation*}
The parameters most likely to explain the observations, given only the observations and definition of the model, are those that maximize this likelihood. Equivalently, we can find the parameters that minimize the negative log-likelihood since the two have the same optima:
\begin{align*}
\beta^* &=& \argmax_\beta P(\tilde{y} | \beta) \\
&=& \argmin_\beta - \ln( P(\tilde{y} | \beta ) \\
&=& \argmin_\beta - N\log{\frac{1}{\sqrt{2\pi\sigma^2}}} - \log{ \prod_{i=1}^N P(\tilde{y}_i | \beta ) }
\end{align*}
The benefit of this is that the terms decouple in the case of normally distributed residuals. Ditching constant factors and collecting the product terms into the exponent the above becomes:
\begin{align*}
\beta^* &=& \argmin_\beta -\ln\left( \exp{-\frac{1}{2}\sum_{i=1}^N \left(\frac{\tilde{y}_i - M_i^T \beta}{\sigma}\right)^2} \right) \\
&=& \argmin_\beta \frac{1}{2\sigma^2} \sum_{i=1}^N \left( \tilde{y}_i - M_i^T \beta \right)^2
\end{align*}
which gives the least-squares version.
Least Squares & MAP
We can also add a prior for the parameters \(\beta\), e.g. \(\beta_i \sim \mathcal{N}(0,\sigma_\beta)\). In this case, each component of \(\beta\) is independent. The MAP estimate for \(\beta\) is then:
\begin{align*}
\beta^* &=& \argmax_\beta P(\tilde{y} | \beta) P(\beta) \\
&=& \argmax_\beta \prod_i P(\tilde{y}_i | \beta) \prod_j P(\beta_j) \\
&=& \argmax_\beta \prod_i \frac{1}{\sqrt{2\pi\sigma^2}}\exp{ -\frac{1}{2}\left(\frac{e_i}{\sigma}\right)^2} \prod_j \frac{1}{\sqrt{2\pi\sigma_\beta^2}}\exp{ -\frac{1}{2}\left(\frac{\beta_j}{\sigma_\beta}\right)^2 }
\end{align*}
The same negative log trick can then be used to convert products to sums, also ditching constants, to get:
\begin{align*}
\beta^* &=& \argmin \frac{1}{2\sigma^2} \sum_i e_i^2 + \frac{1}{2\sigma_\beta^2} \sum_j \beta_j^2 \\
&=& \argmin \frac{1}{2\sigma^2} \sum_i \left( \tilde{y}_i - x_i^T \beta \right)^2 + \frac{1}{2\sigma_\beta^2} \sum_j \beta_j^2
\end{align*}
Using different priors will of course give different forms for the second term, e.g. choosing components of \(\beta\) to follow a Laplace distribution \(\beta_j \sim \frac{\lambda}{2} \exp{-\lambda |\beta_j|}\), gives:
\begin{equation*}
\beta^* = \argmin \frac{1}{2\sigma^2} \sum_i \left( \tilde{y}_i - x_i^T \beta \right)^2 + \lambda \sum_j |\beta_j|
\end{equation*}
Dec 13, 2020
The essential matrix relates normalized coordinates in one view with those in another view of the same scene and is widely used in stereo reconstruction algorithms. It is a 3x3 matrix with rank 2, having only 8 degrees of freedom.
Given \(p\) as a normalized point in image P and \(q\) as the corresponding normalied point in another image Q of the same scene, the essential matrix provides the constraint:
\begin{equation*}
q^T E p = 0
\end{equation*}
It's important that \(p\) and \(q\) be normalized homogeneous points, i.e. the following where \([u_p,v_p]\) are the pixel coordinates of point p:
\begin{equation*}
p = K^{-1} \begin{bmatrix} u_p \\ v_p \\ 1 \end{bmatrix}
\end{equation*}
By fixing the extrinsics of image P as \(R_P = I\) and \(t_P = [0,0,0]^T\) the essential matrix relating P and Q can defined by the relationship:
\begin{equation*}
E = t_\times R
\end{equation*}
where \(R\) and \(t\) are the relative transforms of camera Q with respect to camera P and \(t_\times\) is the matrix representation of the the cross-product:
\begin{equation*}
t_\times = \begin{bmatrix} 0 & -t_z & t_y \\ t_z & 0 & -t_x \\ -t_y & t_x & 0 \end{bmatrix}
\end{equation*}
Nov 07, 2019
It's pretty useful to be able to load meshes when doing graphics. One format that is nearly ubiquitous are Wavefront .OBJ files, due largely to their good features-to-complexity ratio. Sure there are better formats, but when you just want to get a mesh into a program it's hard to beat .obj which can be imported and exported from just about anyhwere.
The code below loads and saves .obj files, including material assignments (but not material parameters), normals, texture coordinates and faces of any number of vertices. It supports faces with/without either/both of normals and texture coordinates and (if you can accept 6D vertices) also suports per-vertex colors (a non-standard extension sometimes used for debugging in mesh processing). Faces without either normals or tex-coords assign the invalid value -1 for these entries.
From the returned object, it is pretty easy to do things like sort faces by material indices, split vertices based on differing normals or along texture boundaries and so on. It also has the option to tesselate non-triangular faces, although this only works for convex faces (you should only be using convex faces anyway though!).
# wavefront.py
import numpy as np
class WavefrontOBJ:
def __init__( self, default_mtl='default_mtl' ):
self.path = None # path of loaded object
self.mtllibs = [] # .mtl files references via mtllib
self.mtls = [ default_mtl ] # materials referenced
self.mtlid = [] # indices into self.mtls for each polygon
self.vertices = [] # vertices as an Nx3 or Nx6 array (per vtx colors)
self.normals = [] # normals
self.texcoords = [] # texture coordinates
self.polygons = [] # M*Nv*3 array, Nv=# of vertices, stored as vid,tid,nid (-1 for N/A)
def load_obj( filename: str, default_mtl='default_mtl', triangulate=False ) -> WavefrontOBJ:
"""Reads a .obj file from disk and returns a WavefrontOBJ instance
Handles only very rudimentary reading and contains no error handling!
Does not handle:
- relative indexing
- subobjects or groups
- lines, splines, beziers, etc.
"""
# parses a vertex record as either vid, vid/tid, vid//nid or vid/tid/nid
# and returns a 3-tuple where unparsed values are replaced with -1
def parse_vertex( vstr ):
vals = vstr.split('/')
vid = int(vals[0])-1
tid = int(vals[1])-1 if len(vals) > 1 and vals[1] else -1
nid = int(vals[2])-1 if len(vals) > 2 else -1
return (vid,tid,nid)
with open( filename, 'r' ) as objf:
obj = WavefrontOBJ(default_mtl=default_mtl)
obj.path = filename
cur_mat = obj.mtls.index(default_mtl)
for line in objf:
toks = line.split()
if not toks:
continue
if toks[0] == 'v':
obj.vertices.append( [ float(v) for v in toks[1:]] )
elif toks[0] == 'vn':
obj.normals.append( [ float(v) for v in toks[1:]] )
elif toks[0] == 'vt':
obj.texcoords.append( [ float(v) for v in toks[1:]] )
elif toks[0] == 'f':
poly = [ parse_vertex(vstr) for vstr in toks[1:] ]
if triangulate:
for i in range(2,len(poly)):
obj.mtlid.append( cur_mat )
obj.polygons.append( (poly[0], poly[i-1], poly[i] ) )
else:
obj.mtlid.append(cur_mat)
obj.polygons.append( poly )
elif toks[0] == 'mtllib':
obj.mtllibs.append( toks[1] )
elif toks[0] == 'usemtl':
if toks[1] not in obj.mtls:
obj.mtls.append(toks[1])
cur_mat = obj.mtls.index( toks[1] )
return obj
def save_obj( obj: WavefrontOBJ, filename: str ):
"""Saves a WavefrontOBJ object to a file
Warning: Contains no error checking!
"""
with open( filename, 'w' ) as ofile:
for mlib in obj.mtllibs:
ofile.write('mtllib {}\n'.format(mlib))
for vtx in obj.vertices:
ofile.write('v '+' '.join(['{}'.format(v) for v in vtx])+'\n')
for tex in obj.texcoords:
ofile.write('vt '+' '.join(['{}'.format(vt) for vt in tex])+'\n')
for nrm in obj.normals:
ofile.write('vn '+' '.join(['{}'.format(vn) for vn in nrm])+'\n')
if not obj.mtlid:
obj.mtlid = [-1] * len(obj.polygons)
poly_idx = np.argsort( np.array( obj.mtlid ) )
cur_mat = -1
for pid in poly_idx:
if obj.mtlid[pid] != cur_mat:
cur_mat = obj.mtlid[pid]
ofile.write('usemtl {}\n'.format(obj.mtls[cur_mat]))
pstr = 'f '
for v in obj.polygons[pid]:
# UGLY!
vstr = '{}/{}/{} '.format(v[0]+1,v[1]+1 if v[1] >= 0 else 'X', v[2]+1 if v[2] >= 0 else 'X' )
vstr = vstr.replace('/X/','//').replace('/X ', ' ')
pstr += vstr
ofile.write( pstr+'\n')
A function that round-trips the loader is shown below, the resulting mesh dump.obj can be loaded into Blender and show the same material ids and texture coordinates. If you inspect it (and remove comments) you will see that the arrays match the string in the function:
from wavefront import *
def obj_load_save_example():
data = '''
# slightly edited blender cube
mtllib cube.mtl
v 1.000000 1.000000 -1.000000
v 1.000000 -1.000000 -1.000000
v 1.000000 1.000000 1.000000
v 1.000000 -1.000000 1.000000
v -1.000000 1.000000 -1.000000
v -1.000000 -1.000000 -1.000000
v -1.000000 1.000000 1.000000
v -1.000000 -1.000000 1.000000
vt 0.625000 0.500000
vt 0.875000 0.500000
vt 0.875000 0.750000
vt 0.625000 0.750000
vt 0.375000 0.000000
vt 0.625000 0.000000
vt 0.625000 0.250000
vt 0.375000 0.250000
vt 0.375000 0.250000
vt 0.625000 0.250000
vt 0.625000 0.500000
vt 0.375000 0.500000
vt 0.625000 0.750000
vt 0.375000 0.750000
vt 0.125000 0.500000
vt 0.375000 0.500000
vt 0.375000 0.750000
vt 0.125000 0.750000
vt 0.625000 1.000000
vt 0.375000 1.000000
vn 0.0000 0.0000 -1.0000
vn 0.0000 1.0000 0.0000
vn 0.0000 0.0000 1.0000
vn -1.0000 0.0000 0.0000
vn 1.0000 0.0000 0.0000
vn 0.0000 -1.0000 0.0000
usemtl mat1
# no texture coordinates
f 6//1 5//1 1//1 2//1
usemtl mat2
f 1/5/2 5/6/2 7/7/2 3/8/2
usemtl mat3
f 4/9/3 3/10/3 7/11/3 8/12/3
usemtl mat4
f 8/12/4 7/11/4 5/13/4 6/14/4
usemtl mat5
f 2/15/5 1/16/5 3/17/5 4/18/5
usemtl mat6
# no normals
f 6/14 2/4 4/19 8/20
'''
with open('test_cube.obj','w') as obj:
obj.write( data )
obj = load_obj( 'test_cube.obj' )
save_obj( obj, 'dump.obj' )
if __name__ == '__main__':
obj_load_save_example()
Hope it's useful!
Nov 05, 2019
These are collections of functions that I end up re-implementing frequently.
import numpy as np
def manifold_mesh_neighbors( tris: np.ndarray ) -> np.ndarray:
"""Returns an array of triangles neighboring each triangle
Args:
tris (Nx3 int array): triangle vertex indices
Returns:
nbrs (Nx3 int array): neighbor triangle indices,
or -1 if boundary edge
"""
if tris.shape[1] != 3:
raise ValueError('Expected a Nx3 array of triangle vertex indices')
e2t = {}
for idx,(a,b,c) in enumerate(tris):
e2t[(b,a)] = idx
e2t[(c,b)] = idx
e2t[(a,c)] = idx
nbr = np.full(tris.shape,-1,int)
for idx,(a,b,c) in enumerate(tris):
nbr[idx,0] = e2t[(a,b)] if (a,b) in e2t else -1
nbr[idx,1] = e2t[(b,c)] if (b,c) in e2t else -1
nbr[idx,2] = e2t[(c,a)] if (c,a) in e2t else -1
return nbr
if __name__ == '__main__':
tris = np.array((
(0,1,2),
(0,2,3)
),int)
nbrs = manifold_mesh_neighbors( tris )
tar = np.array((
(-1,-1,1),
(0,-1,-1)
),int)
if not np.allclose(nbrs,tar):
raise ValueError('uh oh.')
Nov 04, 2019
These are collections of functions that I end up re-implementing frequently.
from typing import *
import numpy as np
def closest_rotation( M: np.ndarray ):
U,s,Vt = np.linalg.svd( M[:3,:3] )
if np.linalg.det(U@Vt) < 0:
Vt[2] *= -1.0
return U@Vt
def mat2quat( M: np.ndarray ):
if np.abs(np.linalg.det(M[:3,:3])-1.0) > 1e-5:
raise ValueError('Matrix determinant is not 1')
if np.abs( np.linalg.norm( M[:3,:3].T@M[:3,:3] - np.eye(3)) ) > 1e-5:
raise ValueError('Matrix is not orthogonal')
w = np.sqrt( 1.0 + M[0,0]+M[1,1]+M[2,2])/2.0
x = (M[2,1]-M[1,2])/(4*w)
y = (M[0,2]-M[2,0])/(4*w)
z = (M[1,0]-M[0,1])/(4*w)
return np.array((x,y,z,w),float)
def quat2mat( q: np.ndarray ):
qx,qy,qz,qw = q/np.linalg.norm(q)
return np.array((
(1 - 2*qy*qy - 2*qz*qz, 2*qx*qy - 2*qz*qw, 2*qx*qz + 2*qy*qw),
( 2*qx*qy + 2*qz*qw, 1 - 2*qx*qx - 2*qz*qz, 2*qy*qz - 2*qx*qw),
( 2*qx*qz - 2*qy*qw, 2*qy*qz + 2*qx*qw, 1 - 2*qx*qx - 2*qy*qy),
))
if __name__ == '__main__':
for i in range( 1000 ):
q = np.random.standard_normal(4)
q /= np.linalg.norm(q)
A = quat2mat( q )
s = mat2quat( A )
if np.linalg.norm( s-q ) > 1e-6 and np.linalg.norm( s+q ) > 1e-6:
raise ValueError('uh oh.')
R = closest_rotation( A+np.random.standard_normal((3,3))*1e-6 )
if np.linalg.norm(A-R) > 1e-5:
print( np.linalg.norm( A-R ) )
raise ValueError('uh oh.')